Modules Ecologia Numérica Medidas de diversidade
Medidas de diversidade

Desafios da mensuração da diversidade
Vimos que as comunidades biológicas são estruturas complexas, com muitas informações. Para descrever uma comunidades biológica usamos com frequência duas dessas infromações:
- Riqueza
- Abundância específica (de cada espécie)
A riqueza em si é uma medida de diversidade. Ela informa quantas espécies há numa comunidade mas despreza suas abundâncias.
Compare as comunidades abaixo

Perceba que os valores de riqueza são exatamente iguais para cada comunidade 4 espécies.
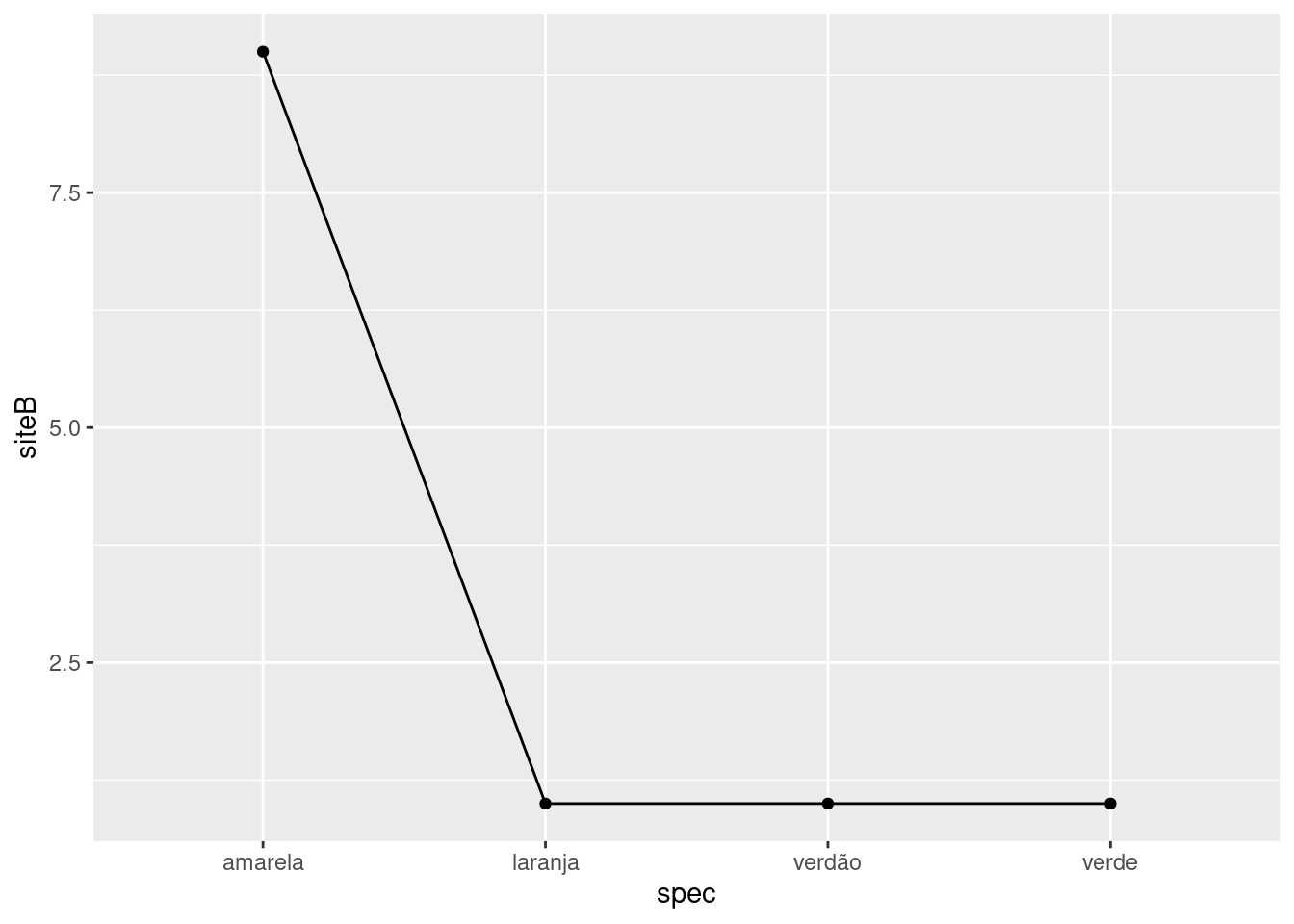
Mas, há uma desbalanço tremendo de abundâncias. A árvore-amarela responde por 25% da abundância da comunidade A enquanto que responde por 75% dos indivíduos da comunidade B.
A importância das curvas de rank-abundância
Se você graficar suas comunidades com uma curva de SAD (species abundance distribution) que é equivalente a uma de rank-abundância, vai perceber que o padrão de distribuição das abundâncias é bem diferente.
Comunidade A
tibble(
spec= c("amarela", "verde","laranja","verdão"),
siteA = (rep(3,4)),
siteB = c(9,1,1,1),
)->comm_ex
comm_ex
## # A tibble: 4 × 3
## spec siteA siteB
## <chr> <dbl> <dbl>
## 1 amarela 3 9
## 2 verde 3 1
## 3 laranja 3 1
## 4 verdão 3 1
Gráfico site A
ggplot(comm_ex, aes(spec, siteA, group=1))+geom_point()+geom_line()
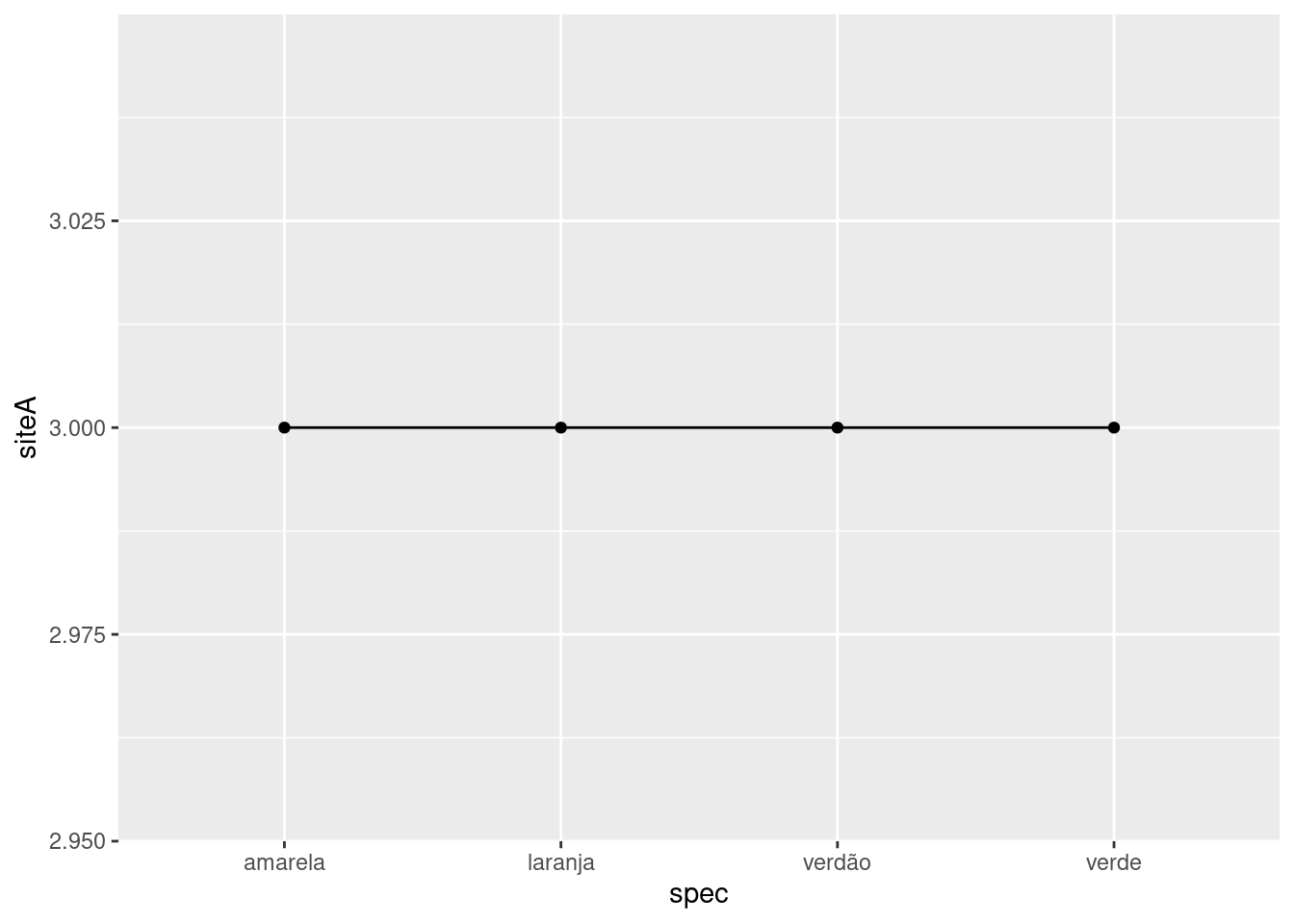
Gráfico site B
ggplot(comm_ex, aes(spec, siteB, group=1))+geom_point()+geom_line()
Índices de diversidade
Riqueza
specnumber(comm_ex$siteA)
## [1] 4
specnumber(comm_ex$siteB)
## [1] 4
Índice de Shannon
diversity(comm_ex$siteA)
## [1] 1.386294
diversity(comm_ex$siteB)
## [1] 0.8369882
ìndice de Simpson
diversity(comm_ex$siteA, index = "simpson")
## [1] 0.75
diversity(comm_ex$siteB, index = "simpson")
## [1] 0.4166667
Agora dê uma lida sobre os índices de diversidade biológica clássicos e tente diferenciar pelo menos esses dois acima.
Qual índice de diversidade usar?
Exercício
- Use a base de dados ‘composicao_especies’ que pode baixar usando os coomandos abaixo
## Pacotes
library(devtools)
## Carregando pacotes exigidos: usethis
##
## Attaching package: 'devtools'
## The following object is masked from 'package:permute':
##
## check
library(ecodados) # para instalar isso é preciso o comado #devtools::install_github("paternogbc/ecodados")
library (vegan)
library(ggplot2)
library(BiodiversityR)
## Carregando pacotes exigidos: tcltk
## BiodiversityR 2.14-4: Use command BiodiversityRGUI() to launch the Graphical User Interface;
## to see changes use BiodiversityRGUI(changeLog=TRUE, backward.compatibility.messages=TRUE)
## Dados
composicao_especies <- ecodados::composicao_anuros_div_taxonomica
precipitacao <- ecodados::precipitacao_div_taxonomica
-
Explore as bases de dados “composicao_especies”
-
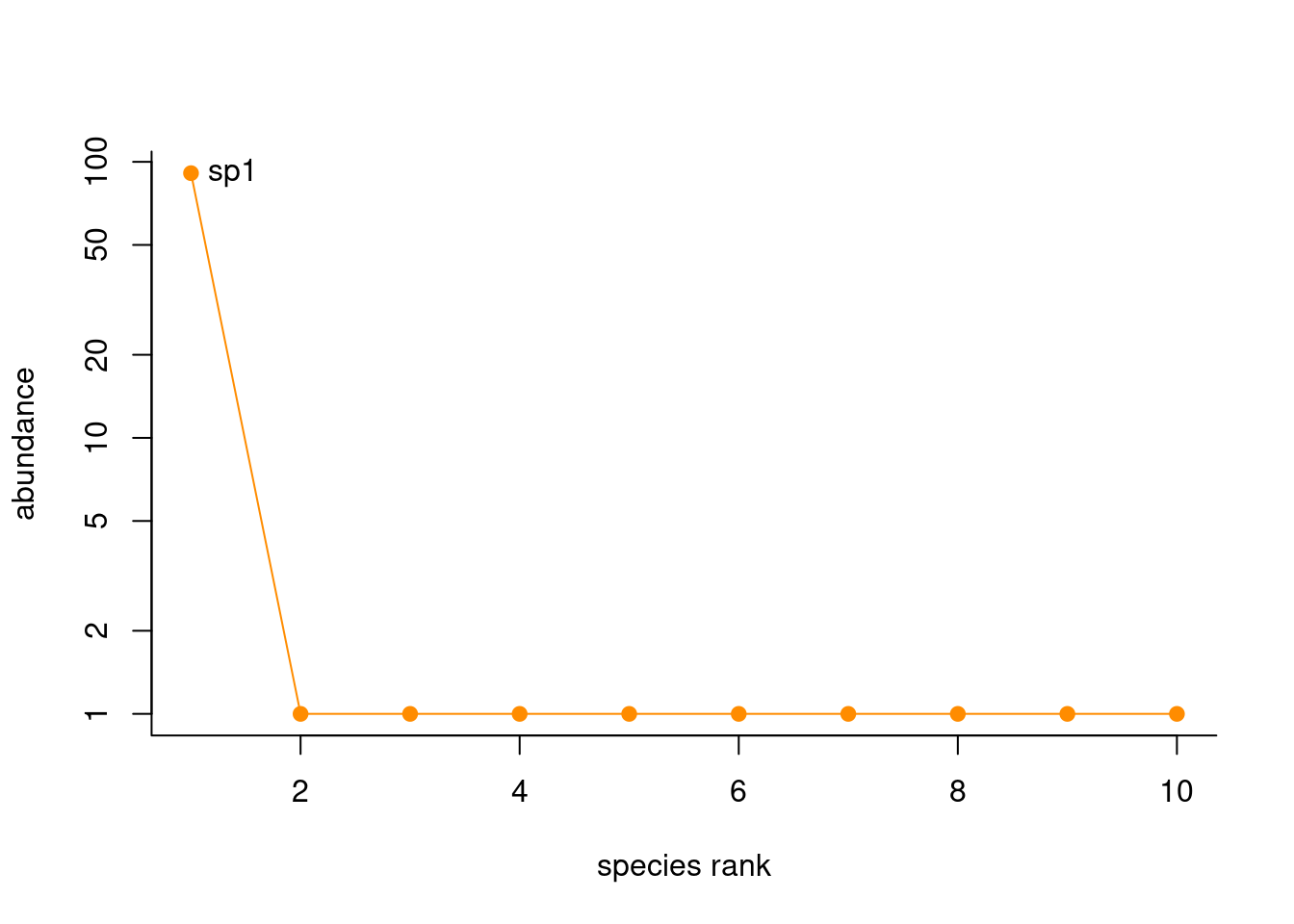
Faça algumas curvas de rank-abundância como essa abaixo
rank_com2 <- rankabundance(composicao_especies[2, composicao_especies[2,] > 0]) # Note que fiz apenas para uma comunidade, a comm 2; Faça para mais de uma repetindo várias vezes esse comando e dando nomes distintos aos objetos
## Warning in qt(0.975, df = n - 1): NaNs produzidos
rankabunplot(rank_com2, scale = "logabun", specnames = c(1),
pch = 19, col = "darkorange")# para fazer vários gráficos, basta repetir os comandos
- Calcule índices de diversidade de espécies. Todos os que conhecer e quiser e comente os mesmos.
riqueza_res <- specnumber(composicao_especies)
riqueza_res
## Com_1 Com_2 Com_3 Com_4 Com_5 Com_6 Com_7 Com_8 Com_9 Com_10
## 10 10 5 5 5 6 2 4 6 4
shannon_res <- diversity(composicao_especies, index = "shannon", MARGIN = 1)
shannon_res
## Com_1 Com_2 Com_3 Com_4 Com_5 Com_6 Com_7 Com_8
## 2.3025851 0.5002880 0.9580109 1.6068659 1.4861894 1.5607038 0.6931472 1.1058899
## Com_9 Com_10
## 1.7140875 1.2636544
simpson_res <- diversity(composicao_especies, index = "simpson", MARGIN = 1)
simpson_res
## Com_1 Com_2 Com_3 Com_4 Com_5 Com_6 Com_7 Com_8
## 0.9000000 0.1710000 0.4814815 0.7989636 0.7587500 0.7674858 0.5000000 0.5850000
## Com_9 Com_10
## 0.8088889 0.6942149
- Teste a relação dos índices com a precipitação
precipitacao
## prec
## Com_1 3200
## Com_2 3112
## Com_3 2800
## Com_4 1800
## Com_5 2906
## Com_6 3005
## Com_7 930
## Com_8 1000
## Com_9 1300
## Com_10 987
## Juntando todos os dados em um único data frame
dados_div <- data.frame(precipitacao$prec, riqueza_res,shannon_res,
simpson_res)
## Renomeando as colunas
colnames(dados_div) <- c("Precipitacao", "Riqueza", "Shannon", "Simpson")
## ANOVA
anova_shan <- lm(Shannon ~ Precipitacao, data = dados_div)
anova(anova_shan)
## Analysis of Variance Table
##
## Response: Shannon
## Df Sum Sq Mean Sq F value Pr(>F)
## Precipitacao 1 0.10989 0.10989 0.3627 0.5637
## Residuals 8 2.42366 0.30296
- Faça um plot para cada relação!